![]()
Appian New 2025 ACD301 Sample Questions Reliable ACD301 Test Engine
Feel Appian ACD301 Dumps PDF Will likely be The best Option
Appian ACD301 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
NEW QUESTION # 14
Your Appian project just went live with the following environment setup: DEV > TEST (SIT/UAT) > PROD. Your client is considering adding a support team to manage production defects and minor enhancements, while the original development team focuses on Phase 2. Your client is asking you for a new environment strategy that will have the least impact on Phase 2 development work. Which option involves the lowest additional server cost and the least code retrofit effort?
- A. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD Production support work stream: DEV2 > TEST (SIT/UAT) > PROD
- B. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD
Production support work stream: DEV > TEST2 (SIT/UAT) > PROD - C. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD Production support work stream: DEV2 > STAGE (SIT/UAT) > PROD
- D. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD Production support work stream: DEV > TEST2 (SIT/UAT) > PROD
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The goal is to design an environment strategy that minimizes additional server costs and code retrofit effort while allowing the support team to manage production defects and minor enhancements without disrupting the Phase 2 development team. The current setup (DEV > TEST (SIT/UAT) > PROD) uses a single development and testing pipeline, and the client wants to segregate support activities from Phase 2 development. Appian's Environment Management Best Practices emphasize scalability, cost efficiency, and minimal refactoring when adjusting environments.
Option C (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):
This option is the most cost-effective and requires the least code retrofit effort. It leverages the existing DEV environment for both teams but introduces a separate TEST2 environment for the support team's SIT/UAT activities. Since DEV is already shared, no new development server is needed, minimizing server costs. The existing code in DEV and TEST can be reused for TEST2 by exporting and importing packages, with minimal adjustments (e.g., updating environment-specific configurations). The Phase 2 team continues using the original TEST environment, avoiding disruption. Appian supports multiple test environments branching from a single DEV, and the PROD environment remains shared, aligning with the client's goal of low impact on Phase 2. The support team can handle defects and enhancements in TEST2 without interfering with development workflows.
Option A (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):
This introduces a STAGE environment for UAT in the Phase 2 stream, adding complexity and potentially requiring code updates to accommodate the new environment (e.g., adjusting deployment scripts). It also requires a new TEST2 server, increasing costs compared to Option C, where TEST2 reuses existing infrastructure.
Option B (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV2 > STAGE (SIT/UAT) > PROD):
This option adds both a DEV2 server for the support team and a STAGE environment, significantly increasing server costs. It also requires refactoring code to support two development environments (DEV and DEV2), including duplicating or synchronizing objects, which is more effort than reusing a single DEV.
Option D (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV2 > TEST (SIT/UAT) > PROD):
This introduces a DEV2 server for the support team, adding server costs. Sharing the TEST environment between teams could lead to conflicts (e.g., overwriting test data), potentially disrupting Phase 2 development. Code retrofit effort is higher due to managing two DEV environments and ensuring TEST compatibility.
Cost and Retrofit Analysis:
Server Cost: Option C avoids new DEV or STAGE servers, using only an additional TEST2, which can often be provisioned on existing hardware or cloud resources with minimal cost. Options A, B, and D require additional servers (TEST2, DEV2, or STAGE), increasing expenses.
Code Retrofit: Option C minimizes changes by reusing DEV and PROD, with TEST2 as a simple extension. Options A and B require updates for STAGE, and B and D involve managing multiple DEV environments, necessitating more significant refactoring.
Appian's recommendation for environment strategies in such scenarios is to maximize reuse of existing infrastructure and avoid unnecessary environment proliferation, making Option C the optimal choice.
NEW QUESTION # 15
You are running an inspection as part of the first deployment process from TEST to PROD. You receive a notice that one of your objects will not deploy because it is dependent on an object from an application owned by a separate team.
What should be your next step?
- A. Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints.
- B. Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk.
- C. Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD.
- D. Halt the production deployment and contact the other team for guidance on promoting the object to PROD.
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, managing a deployment from TEST to PROD requires careful handling of dependencies, especially when objects from another team's application are involved. The scenario describes a dependency issue during deployment, signaling a need for collaboration and governance. Let's evaluate each option:
A . Create your own object with the same code base, replace the dependent object in the application, and deploy to PROD:
This approach involves duplicating the object, which introduces redundancy, maintenance risks, and potential version control issues. It violates Appian's governance principles, as objects should be owned and managed by their respective teams to ensure consistency and avoid conflicts. Appian's deployment best practices discourage duplicating objects unless absolutely necessary, making this an unsustainable and risky solution.
B . Halt the production deployment and contact the other team for guidance on promoting the object to PROD:
This is the correct step. When an object from another application (owned by a separate team) is a dependency, Appian's deployment process requires coordination to ensure both applications' objects are deployed in sync. Halting the deployment prevents partial deployments that could break functionality, and contacting the other team aligns with Appian's collaboration and governance guidelines. The other team can provide the necessary object version, adjust their deployment timeline, or resolve the dependency, ensuring a stable PROD environment.
C . Check the dependencies of the necessary object. Deploy to PROD if there are few dependencies and it is low risk:
This approach risks deploying an incomplete or unstable application if the dependency isn't fully resolved. Even with "few dependencies" and "low risk," deploying without the other team's object could lead to runtime errors or broken functionality in PROD. Appian's documentation emphasizes thorough dependency management during deployment, requiring all objects (including those from other applications) to be promoted together, making this risky and not recommended.
D . Push a functionally viable package to PROD without the dependencies, and plan the rest of the deployment accordingly with the other team's constraints:
Deploying without dependencies creates an incomplete solution, potentially leaving the application non-functional or unstable in PROD. Appian's deployment process ensures all dependencies are included to maintain application integrity, and partial deployments are discouraged unless explicitly planned (e.g., phased rollouts). This option delays resolution and increases risk, contradicting Appian's best practices for Production stability.
Conclusion: Halting the production deployment and contacting the other team for guidance (B) is the next step. It ensures proper collaboration, aligns with Appian's governance model, and prevents deployment errors, providing a safe and effective resolution.
Reference:
Appian Documentation: "Deployment Best Practices" (Managing Dependencies Across Applications).
Appian Lead Developer Certification: Application Management Module (Cross-Team Collaboration).
Appian Best Practices: "Handling Production Deployments" (Dependency Resolution).
NEW QUESTION # 16
You are required to configure a connection so that Jira can inform Appian when specific tickets change (using a webhook). Which three required steps will allow you to connect both systems?
- A. Create a new API Key and associate a service account.
- B. Configure the connection in Jira specifying the URL and credentials.
- C. Create a Web API object and set up the correct security.
- D. Give the service account system administrator privileges.
- E. Create an integration object from Appian to Jira to periodically check the ticket status.
Answer: A,B,C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Configuring a webhook connection from Jira to Appian requires setting up a mechanism for Jira to push ticket change notifications to Appian in real-time. This involves creating an endpoint in Appian to receive the webhook and configuring Jira to send the data. Appian's Integration Best Practices and Web API documentation provide the framework for this process.
Option A (Create a Web API object and set up the correct security):
This is a required step. In Appian, a Web API object serves as the endpoint to receive incoming webhook requests from Jira. You must define the API structure (e.g., HTTP method, input parameters) and configure security (e.g., basic authentication, API key, or OAuth) to validate incoming requests. Appian recommends using a service account with appropriate permissions to ensure secure access, aligning with the need for a controlled webhook receiver.
Option B (Configure the connection in Jira specifying the URL and credentials):
This is essential. In Jira, you need to set up a webhook by providing the Appian Web API's URL (e.g., https://<appian-site>/suite/webapi/<web-api-name>) and the credentials or authentication method (e.g., API key or basic auth) that match the security setup in Appian. This ensures Jira can successfully send ticket change events to Appian.
Option C (Create a new API Key and associate a service account):
This is necessary for secure authentication. Appian recommends using an API key tied to a service account for webhook integrations. The service account should have permissions to process the incoming data (e.g., write to a process or data store) but not excessive privileges. This step complements the Web API security setup and Jira configuration.
Option D (Give the service account system administrator privileges):
This is unnecessary and insecure. System administrator privileges grant broad access, which is overkill for a webhook integration. Appian's security best practices advocate for least-privilege principles, limiting the service account to the specific objects or actions needed (e.g., executing the Web API).
Option E (Create an integration object from Appian to Jira to periodically check the ticket status):
This is incorrect for a webhook scenario. Webhooks are push-based, where Jira notifies Appian of changes. Creating an integration object for periodic polling (pull-based) is a different approach and not required for the stated requirement of Jira informing Appian via webhook.
These three steps (A, B, C) establish a secure, functional webhook connection without introducing unnecessary complexity or security risks.
Reference:
The three required steps that will allow you to connect both systems are:
A . Create a Web API object and set up the correct security. This will allow you to define an endpoint in Appian that can receive requests from Jira via webhook. You will also need to configure the security settings for the Web API object, such as authentication method, allowed origins, and access control.
B . Configure the connection in Jira specifying the URL and credentials. This will allow you to set up a webhook in Jira that can send requests to Appian when specific tickets change. You will need to specify the URL of the Web API object in Appian, as well as any credentials required for authentication.
C . Create a new API Key and associate a service account. This will allow you to generate a unique token that can be used for authentication between Jira and Appian. You will also need to create a service account in Appian that has permissions to access or update data related to Jira tickets.
The other options are incorrect for the following reasons:
D . Give the service account system administrator privileges. This is not required and could pose a security risk, as giving system administrator privileges to a service account could allow it to perform actions that are not related to Jira tickets, such as modifying system settings or accessing sensitive data.
E . Create an integration object from Appian to Jira to periodically check the ticket status. This is not required and could cause unnecessary overhead, as creating an integration object from Appian to Jira would involve polling Jira for ticket status changes, which could consume more resources than using webhook notifications. Verified Reference: Appian Documentation, section "Web API" and "API Keys".
NEW QUESTION # 17
You add an index on the searched field of a MySQL table with many rows (>100k). The field would benefit greatly from the index in which three scenarios?
- A. The field contains a textual short business code.
- B. The field contains a structured JSON.
- C. The field contains many datetimes, covering a large range.
- D. The field contains long unstructured text such as a hash.
- E. The field contains big integers, above and below 0.
Answer: A,C,E
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Adding an index to a searched field in a MySQL table with over 100,000 rows improves query performance by reducing the number of rows scanned during searches, joins, or filters. The benefit of an index depends on the field's data type, cardinality (uniqueness), and query patterns. MySQL indexing best practices, as aligned with Appian's Database Optimization Guidelines, highlight scenarios where indices are most effective.
Option A (The field contains a textual short business code):
This benefits greatly from an index. A short business code (e.g., a 5-10 character identifier like "CUST123") typically has high cardinality (many unique values) and is often used in WHERE clauses or joins. An index on this field speeds up exact-match queries (e.g., WHERE business_code = 'CUST123'), which are common in Appian applications for lookups or filtering.
Option C (The field contains many datetimes, covering a large range):
This is highly beneficial. Datetime fields with a wide range (e.g., transaction timestamps over years) are frequently queried with range conditions (e.g., WHERE datetime BETWEEN '2024-01-01' AND '2025-01-01') or sorting (e.g., ORDER BY datetime). An index on this field optimizes these operations, especially in large tables, aligning with Appian's recommendation to index time-based fields for performance.
Option D (The field contains big integers, above and below 0):
This benefits significantly. Big integers (e.g., IDs or quantities) with a broad range and high cardinality are ideal for indexing. Queries like WHERE id > 1000 or WHERE quantity < 0 leverage the index for efficient range scans or equality checks, a common pattern in Appian data store queries.
Option B (The field contains long unstructured text such as a hash):
This benefits less. Long unstructured text (e.g., a 128-character SHA hash) has high cardinality but is less efficient for indexing due to its size. MySQL indices on large text fields can slow down writes and consume significant storage, and full-text searches are better handled with specialized indices (e.g., FULLTEXT), not standard B-tree indices. Appian advises caution with indexing large text fields unless necessary.
Option E (The field contains a structured JSON):
This is minimally beneficial with a standard index. MySQL supports JSON fields, but a regular index on the entire JSON column is inefficient for large datasets (>100k rows) due to its variable structure. Generated columns or specialized JSON indices (e.g., using JSON_EXTRACT) are required for targeted queries (e.g., WHERE JSON_EXTRACT(json_col, '$.key') = 'value'), but this requires additional setup beyond a simple index, reducing its immediate benefit.
For a table with over 100,000 rows, indices are most effective on fields with high selectivity and frequent query usage (e.g., short codes, datetimes, integers), making A, C, and D the optimal scenarios.
NEW QUESTION # 18
You are on a call with a new client, and their program lead is concerned about how their legacy systems will integrate with Appian. The lead wants to know what authentication methods are supported by Appian. Which three authentication methods are supported?
- A. CAC
- B. Biometrics
- C. SAML
- D. API Keys
- E. OAuth
- F. Active Directory
Answer: C,E,F
Explanation:
Comprehensive and Detailed In-Depth Explanation:As an Appian Lead Developer, addressing a client's concerns about integrating legacy systems with Appian requires accurately identifying supported authentication methods for system-to-system communication or user access. The question focuses on Appian' s integration capabilities, likely for both user authentication (e.g., SSO) and API authentication, as legacy system integration often involves both. Appian's documentation outlines supported methods in its Connected Systems and security configurations. Let's evaluate each option:
* A. API Keys:API Key authentication involves a static key sent in requests (e.g., via headers). Appian supports this for outbound integrations in Connected Systems (e.g., HTTP Authentication with an API key), allowing legacy systems to authenticate Appian calls. However, it's not a user authentication method for Appian's platform login-it's for system-to-system integration. While supported, it's less common for legacy system SSO or enterprise use cases compared to other options, making it a lower- priority choice here.
* B. Biometrics:Biometrics (e.g., fingerprint, facial recognition) isn't natively supported by Appian for platform authentication or integration. Appian relies on standard enterprise methods (e.g., username
/password, SSO), and biometric authentication would require external identity providers or custom clients, not Appian itself. Documentation confirms no direct biometric support, ruling this out as an Appian-supported method.
* C. SAML:Security Assertion Markup Language (SAML) is fully supported by Appian for user authentication via Single Sign-On (SSO). Appian integrates with SAML 2.0 identity providers (e.g., Okta, PingFederate), allowing users to log in using credentials from legacy systems that support SAML- based SSO. This is a key enterprise method, widely used for integrating with existing identity management systems, and explicitly listed in Appian's security configuration options-making it a top choice.
* D. CAC:Common Access Card (CAC) authentication, often used in government contexts with smart cards, isn't natively supported by Appian as a standalone method. While Appian can integrate with CAC via SAML or PKI (Public Key Infrastructure) through an identity provider, it's not a direct Appian authentication option. Documentation mentions smart card support indirectly via SSO configurations, but CAC itself isn't explicitly listed, making it less definitive than other methods.
* E. OAuth:OAuth (specifically OAuth 2.0) is supported by Appian for both outbound integrations (e.g., Authorization Code Grant, Client Credentials) and inbound API authentication (e.g., securing Appian Web APIs). For legacy system integration, Appian can use OAuth to authenticate with APIs (e.g., Google, Salesforce) or allow legacy systems to call Appian services securely. Appian's Connected System framework includes OAuth configuration, making it a versatile, standards-based method highly relevant to the client's needs.
* F. Active Directory:Active Directory (AD) integration via LDAP (Lightweight Directory Access Protocol) is supported for user authentication in Appian. It allows synchronization of users and groups from AD, enabling SSO or direct login with AD credentials. For legacy systems using AD as an identity store, this is a seamless integration method. Appian's documentation confirms LDAP/AD as a core authentication option, widely adopted in enterprise environments-making it a strong fit.
Conclusion: The three supported authentication methods are C (SAML), E (OAuth), and F (Active Directory).
These align with Appian's enterprise-grade capabilities for legacy system integration: SAML for SSO, OAuth for API security, and AD for user management. API Keys (A) are supported but less prominent for user authentication, CAC (D) is indirect, and Biometrics (B) isn't supported natively. This selection reassures the client of Appian's flexibility with common legacy authentication standards.
References:
* Appian Documentation: "Authentication for Connected Systems" (OAuth, API Keys).
* Appian Documentation: "Configuring Authentication" (SAML, LDAP/Active Directory).
* Appian Lead Developer Certification: Integration Module (Authentication Methods).
NEW QUESTION # 19
You are just starting with a new team that has been working together on an application for months. They ask you to review some of their views that have been degrading in performance. The views are highly complex with hundreds of lines of SQL. What is the first step in troubleshooting the degradation?
- A. Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed.
- B. Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge.
- C. Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance.
- D. Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:Troubleshooting performance degradation in complex SQL views within an Appian application requires a systematic approach. The views, described as having hundreds of lines of SQL, suggest potential issues with query execution, indexing, or join efficiency. As a new team member, the first step should focus on quickly identifying the root cause without overhauling the system prematurely. Appian's Performance Troubleshooting Guide and database optimization best practices provide the framework for this process.
* Option B (Run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge):This is the recommended first step. Running an EXPLAIN statement (or equivalent, such as EXPLAIN PLAN in some databases) analyzes the query execution plan, revealing details like full table scans, missing indices, or inefficient joins. This technical analysis can identify immediate optimization opportunities (e.g., adding indices or rewriting subqueries) without requiring business input, allowing you to address low-hanging fruit quickly. Appian encourages using database tools to diagnose performance issues before involving stakeholders, making this a practical starting point as you familiarize yourself with the application.
* Option A (Go through the entire database structure to obtain an overview, ensure you understand the business needs, and then normalize the tables to optimize performance):This is too broad and time-consuming as a first step. Understanding business needs and normalizing tables are valuable but require collaboration with the team and stakeholders, delaying action. It's better suited for a later phase after initial technical analysis.
* Option C (Go through all of the tables one by one to identify which of the grouped by, ordered by, or joined keys are currently indexed):Manually checking indices is useful but inefficient without first knowing which queries are problematic. The EXPLAIN statement provides targeted insights into index usage, making it a more direct initial step than a manual table-by-table review.
* Option D (Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure):Identifying null values and planning restructures is a long-term optimization strategy, not a first step. It requires team input and may not address the immediate performance degradation, which is better tackled with query-level diagnostics.
Starting with an EXPLAIN statement allows you to gather data-driven insights, align with Appian's performance troubleshooting methodology, and proceed with informed optimizations.
References:Appian Documentation - Performance Troubleshooting Guide, Appian Lead Developer Training
- Database Optimization, MySQL/PostgreSQL Documentation - EXPLAIN Statement.
NEW QUESTION # 20
Your Appian project just went live with the following environment setup: DEV > TEST (SIT/UAT) > PROD.
Your client is considering adding a support team to manage production defects and minor enhancements, while the original development team focuses on Phase 2. Your client is asking you for a new environment strategy that will have the least impact on Phase 2 development work. Which optioninvolves the lowest additional server cost and the least code retrofit effort?
- A. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD Production support work stream: DEV2 > TEST (SIT/UAT) > PROD
- B. Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD Production support work stream: DEV > TEST2 (SIT/UAT) > PROD
- C. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD Production support work stream: DEV2 > STAGE (SIT/UAT) > PROD
- D. Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD Production support work stream: DEV > TEST2 (SIT/UAT) > PROD
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:The goal is to design an environment strategy that minimizes additional server costs and code retrofit effort while allowing the support team to manage production defects and minor enhancements without disrupting the Phase 2 development team. The current setup (DEV > TEST (SIT/UAT) > PROD) uses a single development and testing pipeline, and the client wants to segregate support activities from Phase 2 development. Appian's Environment Management Best Practices emphasize scalability, cost efficiency, and minimal refactoring when adjusting environments.
* Option C (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):This option is the most cost-effective and requires the least code retrofit effort. It leverages the existing DEV environment for both teams but introduces a separate TEST2 environment for the support team's SIT/UAT activities. Since DEV is already shared, no new development server is needed, minimizing server costs. The existing code in DEV and TEST can be reused for TEST2 by exporting and importing packages, with minimal adjustments (e.g., updating environment-specific configurations). The Phase 2 team continues using the original TEST environment, avoiding disruption. Appian supports multiple test environments branching from a single DEV, and the PROD environment remains shared, aligning with the client's goal of low impact on Phase 2. The support team can handle defects and enhancements in TEST2 without interfering with development workflows.
* Option A (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV > TEST2 (SIT/UAT) > PROD):This introduces a STAGE environment for UAT in the Phase 2 stream, adding complexity and potentially requiring code updates to accommodate the new environment (e.g., adjusting deployment scripts). It also requires a new TEST2 server, increasing costs compared to Option C, where TEST2 reuses existing infrastructure.
* Option B (Phase 2 development work stream: DEV > TEST (SIT) > STAGE (UAT) > PROD; Production support work stream: DEV2 > STAGE (SIT/UAT) > PROD):This option adds both a DEV2 server for the support team and a STAGE environment, significantly increasing server costs. It also requires refactoring code to support two development environments (DEV and DEV2), including duplicating or synchronizing objects, which is more effort than reusing a single DEV.
* Option D (Phase 2 development work stream: DEV > TEST (SIT/UAT) > PROD; Production support work stream: DEV2 > TEST (SIT/UAT) > PROD):This introduces a DEV2 server for the support team, adding server costs. Sharing the TEST environment between teams could lead to conflicts (e.g., overwriting test data), potentially disrupting Phase 2 development. Code retrofit effort is higher due to managing two DEV environments and ensuring TEST compatibility.
Cost and Retrofit Analysis:
* Server Cost:Option C avoids new DEV or STAGE servers, using only an additional TEST2, which can often be provisioned on existing hardware or cloud resources with minimal cost. Options A, B, and D require additional servers (TEST2, DEV2, or STAGE), increasing expenses.
* Code Retrofit:Option C minimizes changes by reusing DEV and PROD, with TEST2 as a simple extension. Options A and B require updates for STAGE, and B and D involve managing multiple DEV environments, necessitating more significant refactoring.
Appian's recommendation for environment strategies in such scenarios is to maximize reuse of existing infrastructure and avoid unnecessary environment proliferation, making Option C the optimal choice.
References:Appian Documentation - Environment Management and Deployment, Appian Lead Developer Training - Environment Strategy and Cost Optimization.
NEW QUESTION # 21
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage Review the specs for four environments in the following image.
Which environment should you use for load testing7
- A. acme
- B. acmedev
- C. acmeuat
- D. acmetest
Answer: C
Explanation:
The image provides the specifications for four environments in the Appian Cloud:
* acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2
* acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
* acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8
* acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
* Option A (acmeuat):This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
* Option B (acmedev):The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
* Option C (acme):The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
* Option D (acmetest):The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
References:Appian Documentation - Performance Testing Guidelines, Appian Cloud Environment Management, Appian Lead Developer Training - Load Testing Strategies.
NEW QUESTION # 22
You are designing a process that is anticipated to be executed multiple times a day. This process retrieves data from an external system and then calls various utility processes as needed. The main process will not use the results of the utility processes, and there are no user forms anywhere.
Which design choice should be used to start the utility processes and minimize the load on the execution engines?
- A. Start the utility processes via a subprocess asynchronously.
- B. Use the Start Process Smart Service to start the utility processes.
- C. Start the utility processes via a subprocess synchronously.
- D. Use Process Messaging to start the utility process.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a process that executes frequently (multiple times a day) and calls utility processes without using their results requires optimizing performance and minimizing load on Appian's execution engines. The absence of user forms indicates a backend process, so user experience isn't a concern-only engine efficiency matters. Let's evaluate each option:
A . Use the Start Process Smart Service to start the utility processes:
The Start Process Smart Service launches a new process instance independently, creating a separate process in the Work Queue. While functional, it increases engine load because each utility process runs as a distinct instance, consuming engine resources and potentially clogging the Java Work Queue, especially with frequent executions. Appian's performance guidelines discourage unnecessary separate process instances for utility tasks, favoring integrated subprocesses, making this less optimal.
B . Start the utility processes via a subprocess synchronously:
Synchronous subprocesses (e.g., a!startProcess with isAsync: false) execute within the main process flow, blocking until completion. For utility processes not used by the main process, this creates unnecessary delays, increasing execution time and engine load. With frequent daily executions, synchronous subprocesses could strain engines, especially if utility processes are slow or numerous. Appian's documentation recommends asynchronous execution for non-dependent, non-blocking tasks, ruling this out.
C . Use Process Messaging to start the utility process:
Process Messaging (e.g., sendMessage() in Appian) is used for inter-process communication, not for starting processes. It's designed to pass data between running processes, not initiate new ones. Attempting to use it for starting utility processes would require additional setup (e.g., a listening process) and isn't a standard or efficient method. Appian's messaging features are for coordination, not process initiation, making this inappropriate.
D . Start the utility processes via a subprocess asynchronously:
This is the best choice. Asynchronous subprocesses (e.g., a!startProcess with isAsync: true) execute independently of the main process, offloading work to the engine without blocking or delaying the parent process. Since the main process doesn't use the utility process results and there are no user forms, asynchronous execution minimizes engine load by distributing tasks across time, reducing Work Queue pressure during frequent executions. Appian's performance best practices recommend asynchronous subprocesses for non-dependent, utility tasks to optimize engine utilization, making this ideal for minimizing load.
Conclusion: Starting the utility processes via a subprocess asynchronously (D) minimizes engine load by allowing independent execution without blocking the main process, aligning with Appian's performance optimization strategies for frequent, backend processes.
Reference:
Appian Documentation: "Process Model Performance" (Synchronous vs. Asynchronous Subprocesses).
Appian Lead Developer Certification: Process Design Module (Optimizing Engine Load).
Appian Best Practices: "Designing Efficient Utility Processes" (Asynchronous Execution).
NEW QUESTION # 23
You are reviewing log files that can be accessed in Appian to monitor and troubleshoot platform-based issues.
For each type of log file, match the corresponding Information that it provides. Each description will either be used once, or not at all.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.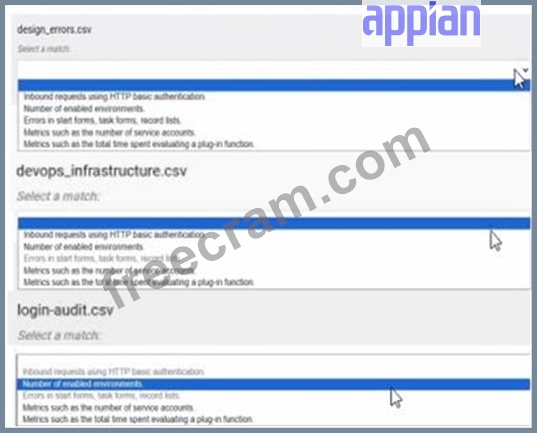
Answer:
Explanation: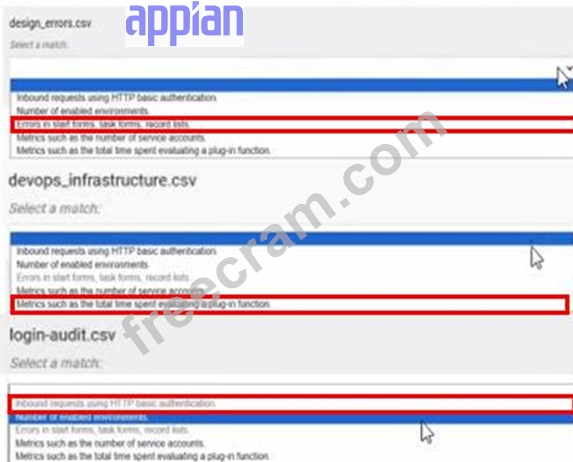
NEW QUESTION # 24
You are reviewing the Engine Performance Logs in Production for a single application that has been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.
During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs. You also notice unattended process activities, including timer events and sending notification emails, are taking far longer to execute than normal.
The client increased the number of CPU cores prior to the application going live.
What is the next recommendation?
- A. Optimize slow-performing user interfaces.
- B. Add more application servers.
- C. Add more engine replicas.
- D. Add execution and analytics shards
Answer: C
Explanation:
As an Appian Lead Developer, analyzing Engine Performance Logs to address performance issues in a Production application requires understanding Appian's architecture and the specific metrics described. The scenario indicates a high "Work Queue - Java Work Queue Size," which reflects a backlog of tasks in the Java Work Queue (managed by Appian engines), and delays in unattended process activities (e.g., timer events, email notifications). These symptoms suggest the Appian engines are overloaded, despite the client increasing CPU cores. Let's evaluate each option:
* A. Add more engine replicas:This is the correct recommendation. In Appian, engine replicas (part of the Appian Engine cluster) handle process execution, including unattended tasks like timers and notifications. A high Java Work Queue Size indicates the engines are overwhelmed by concurrent activity during business hours, causing delays. Adding more engine replicas distributes the workload, reducing queue size and improving performance for both user-driven and unattended tasks. Appian's documentation recommends scaling engine replicas to handle sustained loads, especially in Production with high concurrency. SinceCPU cores were already increased (likely on application servers), the bottleneck is likely the engine capacity, not the servers.
* B. Optimize slow-performing user interfaces:While optimizing user interfaces (e.g., SAIL forms, reports) can improve user experience, the scenario highlights delays in unattended activities (timers, emails), not UI performance. The Java Work Queue Size issue points to engine-level processing, not UI rendering, so this doesn't address the root cause. Appian's performance tuning guidelines prioritize engine scaling for queue-related issues, making this a secondary concern.
* C. Add more application servers:Application servers handle web traffic (e.g., SAIL interfaces, API calls), not process execution or unattended tasks managed by engines. Increasing application servers would help with UI concurrency but wouldn't reduce the Java Work Queue Size or speed up timer
/email processing, as these are engine responsibilities. Since the client already increased CPU cores (likely on application servers), this is redundant and unrelated to the issue.
* D. Add execution and analytics shards:Execution shards (for process data) and analytics shards (for reporting) are part of Appian's data fabric for scalability, but they don't directly address engine workload or Java Work Queue Size. Shards optimize data storage and query performance, not real-time process execution. The logs indicate an engine bottleneck, not a data storage issue, so this isn't relevant.
Appian's documentation confirms shards are for long-term scaling, not immediate performance fixes.
Conclusion: Adding more engine replicas (A) is the next recommendation. It directly resolves the high Java Work Queue Size and delays in unattended tasks, aligning with Appian's architecture for handling concurrent loads in Production. This requires collaboration with system administrators to configure additional replicas in the Appian cluster.
References:
* Appian Documentation: "Engine Performance Monitoring" (Java Work Queue and Scaling Replicas).
* Appian Lead Developer Certification: Performance Optimization Module (Engine Scaling Strategies).
* Appian Best Practices: "Managing Production Performance" (Work Queue Analysis).
NEW QUESTION # 25
You are in a backlog refinement meeting with the development team and the product owner. You review a story for an integration involving a third-party system. A payload will be sent from the Appian system through the integration to the third-party system. The story is 21 points on a Fibonacci scale and requires development from your Appian team as well as technical resources from the third-party system. This item is crucial to your project's success. What are the two recommended steps to ensure this story can be developed effectively?
- A. Identify subject matter experts (SMEs) to perform user acceptance testing (UAT).
- B. Break down the item into smaller stories.
- C. Acquire testing steps from QA resources.
- D. Maintain a communication schedule with the third-party resources.
Answer: B,D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
This question involves a complex integration story rated at 21 points on the Fibonacci scale, indicating significant complexity and effort. Appian Lead Developer best practices emphasize effective collaboration, risk mitigation, and manageable development scopes for such scenarios. The two most critical steps are:
Option C (Maintain a communication schedule with the third-party resources):
Integrations with third-party systems require close coordination, as Appian developers depend on external teams for endpoint specifications, payload formats, authentication details, and testing support. Establishing a regular communication schedule ensures alignment on requirements, timelines, and issue resolution. Appian's Integration Best Practices documentation highlights the importance of proactive communication with external stakeholders to prevent delays and misunderstandings, especially for critical project components.
Option D (Break down the item into smaller stories):
A 21-point story is considered large by Agile standards (Fibonacci scale typically flags anything above 13 as complex). Appian's Agile Development Guide recommends decomposing large stories into smaller, independently deliverable pieces to reduce risk, improve testability, and enable iterative progress. For example, the integration could be split into tasks like designing the payload structure, building the integration object, and testing the connection-each manageable within a sprint. This approach aligns with the principle of delivering value incrementally while maintaining quality.
Option A (Acquire testing steps from QA resources): While QA involvement is valuable, this step is more relevant during the testing phase rather than backlog refinement or development preparation. It's not a primary step for ensuring effective development of the story.
Option B (Identify SMEs for UAT): User acceptance testing occurs after development, during the validation phase. Identifying SMEs is important but not a key step in ensuring the story is developed effectively during the refinement and coding stages.
By choosing C and D, you address both the external dependency (third-party coordination) and internal complexity (story size), ensuring a smoother development process for this critical integration.
NEW QUESTION # 26
You are planning a strategy around data volume testing for an Appian application that queries and writes to a MySQL database. You have administrator access to the Appian application and to the database. What are two key considerations when designing a data volume testing strategy?
- A. Testing with the correct amount of data should be in the definition of done as part of each sprint.
- B. Data model changes must wait until towards the end of the project.
- C. The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation.
- D. Large datasets must be loaded via Appian processes.
- E. Data from previous tests needs to remain in the testing environment prior to loading prepopulated data.
Answer: A,C
Explanation:
Comprehensive and Detailed In-Depth Explanation:Data volume testing ensures an Appian application performs efficiently under realistic data loads, especially when interacting with external databases like MySQL. As an Appian Lead Developer with administrative access, the focus is on scalability, performance, and iterative validation. The two key considerations are:
* Option C (The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation):Determining the appropriate data volume is critical to simulate real-world usage. Appian's Performance Testing Best Practices recommend collaborating with stakeholders (e.g., project sponsors, business analysts) to define expected data sizes based on production scenarios. This ensures the test reflects actual requirements-like peak transaction volumes or record counts-rather than arbitrary guesses. For example, if the application will handle 1 million records in production, stakeholders must specify this to guide test data preparation.
* Option D (Testing with the correct amount of data should be in the definition of done as part of each sprint):Appian's Agile Development Guide emphasizes incorporating performance testing (including data volume) into the Definition of Done (DoD) for each sprint. This ensures that features are validated under realistic conditions iteratively, preventing late-stage performance issues. With admin access, you can query/write to MySQL and assess query performance or write latency with the specified data volume, aligning with Appian's recommendation to "test early and often."
* Option A (Data from previous tests needs to remain in the testing environment prior to loading prepopulated data):This is impractical and risky. Retaining old test data can skew results, introduce inconsistencies, or violate data integrity (e.g., duplicate keys in MySQL). Best practices advocate for a clean, controlled environment with fresh, prepopulated data per test cycle.
* Option B (Large datasets must be loaded via Appian processes):While Appian processes can load data, this is not a requirement. With database admin access, you can use SQL scripts ortools like MySQL Workbench for faster, more efficient data population, bypassing Appian process overhead.
Appian documentation notes this as a preferred method for large datasets.
* Option E (Data model changes must wait until towards the end of the project):Delaying data model changes contradicts Agile principles and Appian's iterative design approach. Changes should occur as needed throughout development to adapt to testing insights, not be deferred.
References:Appian Lead Developer Training - Performance Testing Best Practices, Appian Documentation - Data Management and Testing Strategies.
NEW QUESTION # 27
Your team has deployed an application to Production with an underperforming view. Unexpectedly, the production data is ten times that of what was tested, and you must remediate the issue. What is the best option you can take to mitigate their performance concerns?
- A. Bypass Appian's query rule by calling the database directly with a SQL statement.
- B. Create a table which is loaded every hour with the latest data.
- C. Introduce a data management policy to reduce the volume of data.
- D. Create a materialized view or table.
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, addressing performance issues in production requires balancing Appian's best practices, scalability, and maintainability. The scenario involves an underperforming view due to a significant increase in data volume (ten times the tested amount), necessitating a solution that optimizes performance while adhering to Appian's architecture. Let's evaluate each option:
A . Bypass Appian's query rule by calling the database directly with a SQL statement:
This approach involves circumventing Appian's query rules (e.g., a!queryEntity) and directly executing SQL against the database. While this might offer a quick performance boost by avoiding Appian's abstraction layer, it violates Appian's core design principles. Appian Lead Developer documentation explicitly discourages direct database calls, as they bypass security (e.g., Appian's row-level security), auditing, and portability features. This introduces maintenance risks, dependencies on database-specific logic, and potential production instability-making it an unsustainable and non-recommended solution.
B . Create a table which is loaded every hour with the latest data:
This suggests implementing a staging table updated hourly (e.g., via an Appian process model or ETL process). While this could reduce query load by pre-aggregating data, it introduces latency (data is only fresh hourly), which may not meet real-time requirements typical in Appian applications (e.g., a customer-facing view). Additionally, maintaining an hourly refresh process adds complexity and overhead (e.g., scheduling, monitoring). Appian's documentation favors more efficient, real-time solutions over periodic refreshes unless explicitly required, making this less optimal for immediate performance remediation.
C . Create a materialized view or table:
This is the best choice. A materialized view (or table, depending on the database) pre-computes and stores query results, significantly improving retrieval performance for large datasets. In Appian, you can integrate a materialized view with a Data Store Entity, allowing a!queryEntity to fetch data efficiently without changing application logic. Appian Lead Developer training emphasizes leveraging database optimizations like materialized views to handle large data volumes, as they reduce query execution time while keeping data consistent with the source (via periodic or triggered refreshes, depending on the database). This aligns with Appian's performance optimization guidelines and addresses the tenfold data increase effectively.
D . Introduce a data management policy to reduce the volume of data:
This involves archiving or purging data to shrink the dataset (e.g., moving old records to an archive table). While a long-term data management policy is a good practice (and supported by Appian's Data Fabric principles), it doesn't immediately remediate the performance issue. Reducing data volume requires business approval, policy design, and implementation-delaying resolution. Appian documentation recommends combining such strategies with technical fixes (like C), but as a standalone solution, it's insufficient for urgent production concerns.
Conclusion: Creating a materialized view or table (C) is the best option. It directly mitigates performance by optimizing data retrieval, integrates seamlessly with Appian's Data Store, and scales for large datasets-all while adhering to Appian's recommended practices. The view can be refreshed as needed (e.g., via database triggers or schedules), balancing performance and data freshness. This approach requires collaboration with a DBA to implement but ensures a robust, Appian-supported solution.
Reference:
Appian Documentation: "Performance Best Practices" (Optimizing Data Queries with Materialized Views).
Appian Lead Developer Certification: Application Performance Module (Database Optimization Techniques).
Appian Best Practices: "Working with Large Data Volumes in Appian" (Data Store and Query Performance).
NEW QUESTION # 28
You are asked to design a case management system for a client. In addition to storing some basic metadata about a case, one of the client's requirements is the ability for users to update a case. The client would like any user in their organization of 500 people to be able to make these updates. The users are all based in the company's headquarters, and there will be frequent cases where users are attempting to edit the same case. The client wants to ensure no information is lost when these edits occur and does not want the solution to burden their process administrators with any additional effort. Which data locking approach should you recommend?
- A. Allow edits without locking the case CDI.
- B. Design a process report and query to determine who opened the edit form first.
- C. Use the database to implement low-level pessimistic locking.
- D. Add an @Version annotation to the case CDT to manage the locking.
Answer: D
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The requirement involves a case management system where 500 users may simultaneously edit the same case, with a need to prevent data loss and minimize administrative overhead. Appian's data management and concurrency control strategies are critical here, especially when integrating with an underlying database.
Option C (Add an @Version annotation to the case CDT to manage the locking):
This is the recommended approach. In Appian, the @Version annotation on a Custom Data Type (CDT) enables optimistic locking, a lightweight concurrency control mechanism. When a user updates a case, Appian checks the version number of the CDT instance. If another user has modified it in the meantime, the update fails, prompting the user to refresh and reapply changes. This prevents data loss without requiring manual intervention by process administrators. Appian's Data Design Guide recommends @Version for scenarios with high concurrency (e.g., 500 users) and frequent edits, as it leverages the database's native versioning (e.g., in MySQL or PostgreSQL) and integrates seamlessly with Appian's process models. This aligns with the client's no-burden requirement.
Option A (Allow edits without locking the case CDI):
This is risky. Without locking, simultaneous edits could overwrite each other, leading to data loss-a direct violation of the client's requirement. Appian does not recommend this for collaborative environments.
Option B (Use the database to implement low-level pessimistic locking):
Pessimistic locking (e.g., using SELECT ... FOR UPDATE in MySQL) locks the record during the edit process, preventing other users from modifying it until the lock is released. While effective, it can lead to deadlocks or performance bottlenecks with 500 users, especially if edits are frequent. Additionally, managing this at the database level requires custom SQL and increases administrative effort (e.g., monitoring locks), which the client wants to avoid. Appian prefers higher-level solutions like @Version over low-level database locking.
Option D (Design a process report and query to determine who opened the edit form first):
This is impractical and inefficient. Building a custom report and query to track form opens adds complexity and administrative overhead. It doesn't inherently prevent data loss and relies on manual resolution, conflicting with the client's requirements.
The @Version annotation provides a robust, Appian-native solution that balances concurrency, data integrity, and ease of maintenance, making it the best fit.
NEW QUESTION # 29
You need to generate a PDF document with specific formatting. Which approach would you recommend?
- A. Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format.
- B. There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead.
- C. Use the Word Doc from Template smart service in a process model to add the specific format.
- D. Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:As an Appian Lead Developer, generating a PDF with specific formatting is a common requirement, and Appian provides several tools to achieve this. The question emphasizes "specific formatting," which implies precise control over layout, styling, and content structure.
Let's evaluate each option based on Appian's official documentation and capabilities:
* A. Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF:This approach involves designing an interface (e.g., using SAIL components) and relying on the browser's native print-to-PDF feature. While this is feasible for simple content, it lacks precision for "specific formatting." Browser rendering varies across devices and browsers, and print styles (e.g., CSS) are limited in Appian's control. Appian Lead Developer best practices discouragerelying on client-side functionality for critical document generation due to inconsistency and lack of automation. This is not a recommended solution for a production-grade requirement.
* B. Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format:This is the correct choice. The "PDF from XSL-FO Transformation" smart service (available in Appian's process modeling toolkit) allows developers to generate PDFs programmatically with precise formatting using XSL-FO (Extensible Stylesheet Language Formatting Objects). XSL-FO provides fine- grained control over layout, fonts, margins, and styling-ideal for "specific formatting" requirements.
In a process model, you can pass XML data and an XSL-FO stylesheet to this smart service, producing a downloadable PDF. Appian's documentation highlights this as the preferred method for complex PDF generation, making it a robust, scalable, and Appian-native solution.
* C. Use the Word Doc from Template smart service in a process model to add the specific format:This option uses the "Word Doc from Template" smart service to generate a Microsoft Word document from a template (e.g., a .docx file with placeholders). While it supports formatting defined in the template and can be converted to PDF post-generation (e.g., via a manual step or external tool), it's not a direct PDF solution. Appian doesn't natively convert Word to PDF within the platform, requiring additional steps outside the process model. For "specific formatting" in a PDF, this is less efficient and less precise than the XSL-FO approach, as Word templates are better suited for editable documents rather than final PDFs.
* D. There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead:This is incorrect. Appian provides multiple tools for document generation, including PDFs, as evidenced by options B and C. Suggesting a plain email fails to meet the requirement of generating a formatted PDF and contradicts Appian's capabilities. Appian Lead Developer training emphasizes leveraging platform features to meet business needs, ruling out this option entirely.
Conclusion: The PDF from XSL-FO Transformation smart service (B) is the recommended approach. It provides direct PDF generation with specific formatting control within Appian's process model, aligning with best practices for document automation and precision. This method is scalable, repeatable, and fully supported by Appian's architecture.
References:
* Appian Documentation: "PDF from XSL-FO Transformation Smart Service" (Process Modeling > Smart Services).
* Appian Lead Developer Certification: Document Generation Module (PDF Generation Techniques).
* Appian Best Practices: "Generating Documents in Appian" (XSL-FO vs. Template-Based Approaches).
NEW QUESTION # 30
Users must be able to navigate throughout the application while maintaining complete visibility in the application structure and easily navigate to previous locations. Which Appian Interface Pattern would you recommend?
- A. Implement an Activity History pattern to track an organization's activity measures.
- B. Include a Breadcrumbs pattern on applicable interfaces to show the organizational hierarchy.
- C. Use Billboards as Cards pattern on the homepage to prominently display application choices.
- D. Implement a Drilldown Report pattern to show detailed information about report data.
Answer: B
Explanation:
Comprehensive and Detailed In-Depth Explanation:The requirement emphasizes navigation with complete visibility of the application structure and the ability to return to previous locations easily. TheBreadcrumbs patternis specifically designed to meet this need. According to Appian's design best practices, the Breadcrumbs pattern provides a visual trail of the user's navigation path, showing the hierarchy of pages or sections within the application. This allows users to understand their current location relative to the overall structure and quickly navigate back to previous levels by clicking on the breadcrumb links.
* Option A (Billboards as Cards):This pattern is useful for presenting high-level options or choices on a homepage in a visually appealing way. However, it does not address navigation visibility or the ability to return to previous locations, making it irrelevant to the requirement.
* Option B (Activity History):This pattern tracks and displays a log of activities or actions within the application, typically for auditing or monitoring purposes. It does not enhance navigation or provide visibility into the application structure.
* Option C (Drilldown Report):This pattern allows users to explore detailed data within reports by drilling into specific records. While it supports navigation within data, it is not designed for general application navigation or maintaining structural visibility.
* Option D (Breadcrumbs):This is the correct choice as it directly aligns with the requirement. Per Appian's Interface Patterns documentation, Breadcrumbs improve usability by showing ahierarchical path (e.g., Home > Section > Subsection) and enabling backtracking, fulfilling both visibility and navigation needs.
References:Appian Design Guide - Interface Patterns (Breadcrumbs section), Appian Lead Developer Training - User Experience Design Principles.
NEW QUESTION # 31
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage Review the specs for four environments in the following image.
Which environment should you use for load testing7
- A. acme
- B. acmedev
- C. acmeuat
- D. acmetest
Answer: C
Explanation:
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2 acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8 acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4 Load testing assesses an application's performance under increased user load to ensure scalability and stability. Appian's Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat):
This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production's capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client's goal of increasing active users without risking live data.
Option B (acmedev):
The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It's optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme):
The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian's Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest):
The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production's memory and vCPUs. However, it's typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it's less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
NEW QUESTION # 32
Your client's customer management application is finally released to Production. After a few weeks of small enhancements and patches, the client is ready to build their next application. The new application will leverage customer information from the first application to allow the client to launch targeted campaigns for select customers in order to increase sales. As part of the first application, your team had built a section to display key customer information such as their name, address, phone number, how long they have been a customer, etc. A similar section will be needed on the campaign record you are building. One of your developers shows you the new object they are working on for the new application and asks you to review it as they are running into a few issues. What feedback should you give?
- A. Ask the developer to convert the original customer section into a shared object so it can be used by the new application.
- B. Point the developer to the relevant areas in the documentation or Appian Community where they can find more information on the issues they are running into.
- C. Create a duplicate version of that section designed for the campaign record.
- D. Provide guidance to the developer on how to address the issues so that they can proceed with their work.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
The scenario involves reusing a customer information section from an existing application in a new application for campaign management, with the developer encountering issues. Appian's best practices emphasize reusability, efficiency, and maintainability, especially when leveraging existing components across applications.
Option B (Ask the developer to convert the original customer section into a shared object so it can be used by the new application):
This is the recommended approach. Converting the original section into a shared object (e.g., a reusable interface component) allows it to be accessed across applications without duplication. Appian's Design Guide highlights the use of shared components to promote consistency, reduce redundancy, and simplify maintenance. Since the new application requires similar customer data (name, address, etc.), reusing the existing section-after ensuring it is modular and adaptable-addresses the developer's issues while aligning with the client's goal of leveraging prior work. The developer can then adjust the shared object (e.g., via parameters) to fit the campaign context, resolving their issues collaboratively.
Option A (Provide guidance to the developer on how to address the issues so that they can proceed with their work):
While providing guidance is valuable, it doesn't address the root opportunity to reuse existing code. This option focuses on fixing the new object in isolation, potentially leading to duplicated effort if the original section could be reused instead.
Option C (Point the developer to the relevant areas in the documentation or Appian Community where they can find more information on the issues they are running into):
This is a passive approach and delays resolution. As a Lead Developer, offering direct support or a strategic solution (like reusing components) is more effective than redirecting the developer to external resources without context.
Option D (Create a duplicate version of that section designed for the campaign record):
Duplication violates Appian's principle of DRY (Don't Repeat Yourself) and increases maintenance overhead. Any future updates to customer data display logic would need to be applied to multiple objects, risking inconsistencies.
Given the need to leverage existing customer information and the developer's issues, converting the section to a shared object is the most efficient and scalable solution.
NEW QUESTION # 33
You need to generate a PDF document with specific formatting. Which approach would you recommend?
- A. Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format.
- B. There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead.
- C. Use the Word Doc from Template smart service in a process model to add the specific format.
- D. Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF.
Answer: A
Explanation:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, generating a PDF with specific formatting is a common requirement, and Appian provides several tools to achieve this. The question emphasizes "specific formatting," which implies precise control over layout, styling, and content structure. Let's evaluate each option based on Appian's official documentation and capabilities:
A . Create an embedded interface with the necessary content and ask the user to use the browser "Print" functionality to save it as a PDF:
This approach involves designing an interface (e.g., using SAIL components) and relying on the browser's native print-to-PDF feature. While this is feasible for simple content, it lacks precision for "specific formatting." Browser rendering varies across devices and browsers, and print styles (e.g., CSS) are limited in Appian's control. Appian Lead Developer best practices discourage relying on client-side functionality for critical document generation due to inconsistency and lack of automation. This is not a recommended solution for a production-grade requirement.
B . Use the PDF from XSL-FO Transformation smart service to generate the content with the specific format:
This is the correct choice. The "PDF from XSL-FO Transformation" smart service (available in Appian's process modeling toolkit) allows developers to generate PDFs programmatically with precise formatting using XSL-FO (Extensible Stylesheet Language Formatting Objects). XSL-FO provides fine-grained control over layout, fonts, margins, and styling-ideal for "specific formatting" requirements. In a process model, you can pass XML data and an XSL-FO stylesheet to this smart service, producing a downloadable PDF. Appian's documentation highlights this as the preferred method for complex PDF generation, making it a robust, scalable, and Appian-native solution.
C . Use the Word Doc from Template smart service in a process model to add the specific format:
This option uses the "Word Doc from Template" smart service to generate a Microsoft Word document from a template (e.g., a .docx file with placeholders). While it supports formatting defined in the template and can be converted to PDF post-generation (e.g., via a manual step or external tool), it's not a direct PDF solution. Appian doesn't natively convert Word to PDF within the platform, requiring additional steps outside the process model. For "specific formatting" in a PDF, this is less efficient and less precise than the XSL-FO approach, as Word templates are better suited for editable documents rather than final PDFs.
D . There is no way to fulfill the requirement using Appian. Suggest sending the content as a plain email instead:
This is incorrect. Appian provides multiple tools for document generation, including PDFs, as evidenced by options B and C. Suggesting a plain email fails to meet the requirement of generating a formatted PDF and contradicts Appian's capabilities. Appian Lead Developer training emphasizes leveraging platform features to meet business needs, ruling out this option entirely.
Conclusion: The PDF from XSL-FO Transformation smart service (B) is the recommended approach. It provides direct PDF generation with specific formatting control within Appian's process model, aligning with best practices for document automation and precision. This method is scalable, repeatable, and fully supported by Appian's architecture.
Reference:
Appian Documentation: "PDF from XSL-FO Transformation Smart Service" (Process Modeling > Smart Services).
Appian Lead Developer Certification: Document Generation Module (PDF Generation Techniques).
Appian Best Practices: "Generating Documents in Appian" (XSL-FO vs. Template-Based Approaches).
NEW QUESTION # 34
You are planning a strategy around data volume testing for an Appian application that queries and writes to a MySQL database. You have administrator access to the Appian application and to the database. What are two key considerations when designing a data volume testing strategy?
- A. Testing with the correct amount of data should be in the definition of done as part of each sprint.
- B. Data model changes must wait until towards the end of the project.
- C. The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation.
- D. Large datasets must be loaded via Appian processes.
- E. Data from previous tests needs to remain in the testing environment prior to loading prepopulated data.
Answer: A,C
Explanation:
Comprehensive and Detailed In-Depth Explanation:
Data volume testing ensures an Appian application performs efficiently under realistic data loads, especially when interacting with external databases like MySQL. As an Appian Lead Developer with administrative access, the focus is on scalability, performance, and iterative validation. The two key considerations are:
Option C (The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation):
Determining the appropriate data volume is critical to simulate real-world usage. Appian's Performance Testing Best Practices recommend collaborating with stakeholders (e.g., project sponsors, business analysts) to define expected data sizes based on production scenarios. This ensures the test reflects actual requirements-like peak transaction volumes or record counts-rather than arbitrary guesses. For example, if the application will handle 1 million records in production, stakeholders must specify this to guide test data preparation.
Option D (Testing with the correct amount of data should be in the definition of done as part of each sprint):
Appian's Agile Development Guide emphasizes incorporating performance testing (including data volume) into the Definition of Done (DoD) for each sprint. This ensures that features are validated under realistic conditions iteratively, preventing late-stage performance issues. With admin access, you can query/write to MySQL and assess query performance or write latency with the specified data volume, aligning with Appian's recommendation to "test early and often." Option A (Data from previous tests needs to remain in the testing environment prior to loading prepopulated data): This is impractical and risky. Retaining old test data can skew results, introduce inconsistencies, or violate data integrity (e.g., duplicate keys in MySQL). Best practices advocate for a clean, controlled environment with fresh, prepopulated data per test cycle.
Option B (Large datasets must be loaded via Appian processes): While Appian processes can load data, this is not a requirement. With database admin access, you can use SQL scripts or tools like MySQL Workbench for faster, more efficient data population, bypassing Appian process overhead. Appian documentation notes this as a preferred method for large datasets.
Option E (Data model changes must wait until towards the end of the project): Delaying data model changes contradicts Agile principles and Appian's iterative design approach. Changes should occur as needed throughout development to adapt to testing insights, not be deferred.
NEW QUESTION # 35
......
Use Valid New ACD301 Test Notes & ACD301 Valid Exam Guide: https://www.freecram.com/Appian-certification/ACD301-exam-dumps.html
ACD301 exam torrent Appian study guide: https://drive.google.com/open?id=1V-uN17JTwolJoS31LMhti89AdXvE4xvt